
install gcc locally
ensure you can log into seawulf
17. What happens when I build code in C?#
17.1. What is buiding code?#
Building is transforming code from some input format (some text for example) into the final desired format.
This can mean different things in different contexts. For example:
the course website is built from markdown files into html output using jupyter-book
a C program is built from C source code to executable that the machine can understand as the output
We sometimes say that compiling takes code from source to executable, but this process is actually multiple stages and compiling is one of those steps.
We will focus on what has to happen more than how it all happens.
CSC301, 402, 501, 502 go into greater detail on how languages work.
Our goal is to:
(where applicable) give you a preview
get enough understanding of what happens to know where to look when debugging
17.2. How can I authenticate more securely from a terminal?#
Previous notes:
17.3. remember seawulf?#
ssh -l ayman_sandouk seawulf.uri.edu
Or
ssh -l ayman_sandouk@seawulf.uri.edu
ayman_sandouk@seawulf.uri.edu's password:
[ayman_sandouk@seawulf ~]$ pwd
logout
Connection to seawulf.uri.edu closed.
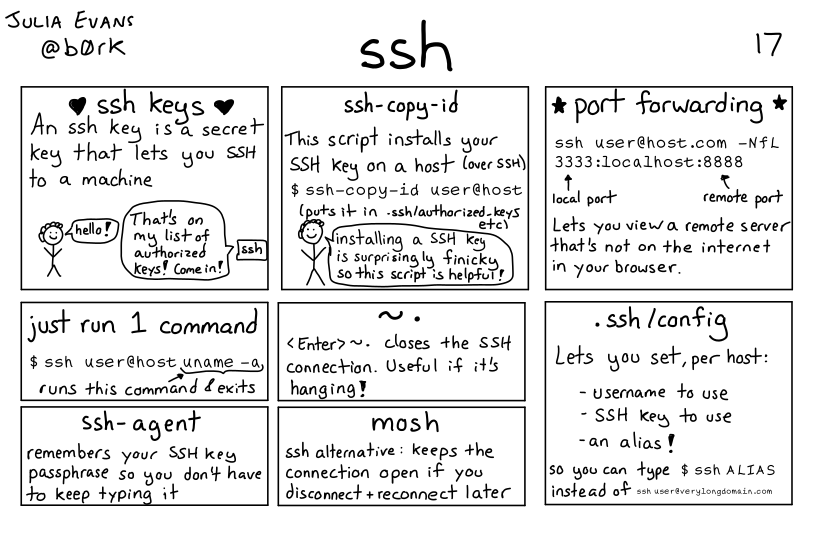
17.4. Creating SSH Keys#
17.5. Using ssh keys to authenticated#
generate a key pair
store the public key on the server
Request to login, tell server your public key, get back a session ID from the server
if it has that public key, then it generates a random string, encrypts it with your public key and sends it back to your computer
On your computer, it decrypts the message + the session ID with your private key then hashes the message and sends it back
the server then hashes its copy of the message and session ID and if the hash received and calculated match, then you are loggied in
Lots more networking detals in the full zine available for purchase or I have a copy if you want to borrow it.
this free zine describes networks at a lower level full zine but does not include ssh
17.6. Generating a Key Pair#
We can use ssh-keygen to create a keys.
-foption allows us to specify the file name of the keys.-toption allows us to specify the algorithm-boption allows us to specify the size
ssh-keygen -f ~/.ssh/seawulf -t rsa -b 1024
17.7. Sending the public key to a server#
again -i to specify the file name
ssh-copy-id -i ~/.ssh/seawulf ayman_sandouk@seawulf.uri.edu
17.8. Logging in#
To login without usng a password you have to tell ssh which key to use:
ssh -i ~/.ssh/seawulf ayman_sandouk@seawulf.uri.edu
Or you can add the following to your ~/.ssh/config file
Host seawulf
Hostname seawulf.uri.edu
Username ayman_sandouk
IdentityFile ~/.ssh/seawulf
and then use
ssh seawulf
17.9. Using SSH Keys#
We are going to work on seawulf so that we all have the same compiler.
To use it we use he -i option and then the path to the private key file
ssh -i ~/seawulf ayman_sandouk@seawulf.uri.edu
Last login: Tue Apr 4 11:53:06 2023 from 172.20.207.131
17.10. Using an interactive session#
Last class we worked on the login node, but that is not best practice.
Today we will use an interactive session using the interactive program.
The login node has limited resources, and is only usually used to connect to the server and possibly run batch jobs from there. The login node resources are shared among many users, so, out of courtesy, we try not to occupy these resources too much or for too long
First we’ll look at its help
Usage: interactive [-c] [-p] [-J] [-w]
Optional arguments:
-c: number of CPU cores to request (default: 1)
-p: partition to run job in (default: general)
-J: job name (default: interactive)
-w: node name
NB: interactive jobs have a time limit of 8 hours.
Written by: Alan Orth <a.orth@cgiar.org>
Then we will start one with all default settings
[ayman_sandouk@seawulf ~]$ interactive
salloc: Granted job allocation 27371
salloc: Waiting for resource configuration
salloc: Nodes n005 are ready for job
it tells us what it is doing while it gets ready.
We see that the prompt changes, now we are @n005 instead of @seawulf, lets check out working directory:
[ayman_sandouk@n005 ~]$ ls
bash-lesson.tar.gz SRR307026_1.fastq
dmel-all-r6.19.gtf SRR307026_2.fastq
dmel_unique_protein_isoforms_fb_2016_01.tsv SRR307027_1.fastq
gene_association.fb SRR307027_2.fastq
SRR307023_1.fastq SRR307028_1.fastq
SRR307023_2.fastq SRR307028_2.fastq
SRR307024_1.fastq SRR307029_1.fastq
SRR307024_2.fastq SRR307029_2.fastq
SRR307025_1.fastq SRR307030_1.fastq
SRR307025_2.fastq SRR307030_2.fastq
our files are still there. The compute node changed, but not our disk space location.
And our working directory is the same:
[ayman_sandouk@n005 ~]$ pwd
/home/ayman_sandouk
still our home directory
We will make an empty directory to work in for today.
[ayman_sandouk@n005 ~]$ mkdir compilec
and go into it to work
[ayman_sandouk@n005 ~]$ cd compilec/
ls
17.11. An overview#
17.12. A simple program#
nano hello.c
and we will put in a simple hello world program
#include <stdio.h>
void main () {
printf("Hello world\n");
}
We will see this is the only file in the folder
ls
hello.c
17.13. Preprocessing with gcc#
First we handle the preprocessing which pulls in headers that are included in our source code. We will use the compiler gcc
We will use gcc for many steps. We will use different options that it offers to do subsets of the complete compile task:
-Estops after preprocessing-omakes it write the .i file and passes the file name for it
gcc -E hello.c -o hello.i
If it succeeds, we see no output, but we can check the folder
ls
now we have a new file
hello.c hello.i
If we think that the .i file might be big, what can we use to compare the two to see the impact of preprocesing?
We can inspect what it does using wc
wc -l hello.c
6 hello.c
we started with just 6 lines of code
and we can compare that to the preprocessed file:
wc -l hello.i
842 hello.i
and see we get a lot more
#include <stdio.h>
void main () {
printf("Hello world\n");
}
Since it is long, we will fist look at the top
head hello.i
# 1 "hello.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "hello.c"
# 1 "/usr/include/stdio.h" 1 3 4
# 27 "/usr/include/stdio.h" 3 4
# 1 "/usr/include/features.h" 1 3 4
# 375 "/usr/include/features.h" 3 4
and the end
tail hello.i
extern void funlockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
# 943 "/usr/include/stdio.h" 3 4
# 2 "hello.c" 2
void main () {
printf("Hello world\n");
}
we see that our original program, is at the end of the file, and the beginning is where the include line has been expanded.
17.14. Compiling#
Next we take our preprocessed file and compile it to get assembly code.
Again, we use gcc:
-Stells it to produce assemblywe will use the preprocessed file as input
gcc -S hello.i
but we can see what it output:
ls
hello.c hello.i hello.s
we have a new file as well with the .s extension. Notice how we didn’t need to use the -o option this time
Again, lets inspect
wc -l hello.s
25 hello.s
this is longer than the source, but not as long as the header. The header contains lots of information that we might need, but the assembly is only what we do.
And it’s manageable, so we inspect it directly:
cat hello.s
.file "hello.c"
.section .rodata
.LC0:
.string "Hello world"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $.LC0, %edi
call puts
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)"
.section .note.GNU-stack,"",@progbits
There are many more steps. These are lower level operations, but they are still text stored in the file.
Hint
Learning more about assembly languages is a good explore badge topic
17.15. Assembling#
Assembling is to take the assembly code and get object code. Assembly is relatively broad and there are families of assembly code, it is also still written for humans to understand it readily. It’s more complex than source code because it is closer to the hardware. The object code however, is specific instructions to your machine and not human readable.
Again, with gcc:
-ctells it to stop at the object file-oagain gives it the name of the file to write
gcc -c hello.s -o hello.o
Again, check what it does by looking at files
ls
hello.c hello.i hello.o hello.s
now we see a new file, the .o
and again check its length
wc -l hello.o
5 hello.o
this is even shorter,
we can check how many characters and words
wc hello.o
5 17 1496 hello.o
it is not even too many characters
let’s look at it
cat hello.o
ELF>?@@
UH???]?Hello worldGCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)zRx
K A?C
?? hello.cmainputs
???????? .symtab.strtab.shstrtab.rela.text.data.bss.rodata.comment.note.GNU-stack.rela.eh_frame @?0
&PP1P
90\.B?W?R@
?
?0a
This is not human readable, though:
17.16. Linking#
Now we can link it all together; in this program there are not a lot of other depdencies, but this fills in anything from libraries and outputs an executble
once again with gcc:
-oflag specifies the name for output-lmtells it to link from the .o file.
gcc -o hello hello.o -lm
ls
hello hello.c hello.i hello.o hello.s
Finally we can run our program
./hello
Hello world
17.17. Putting it all together#
We can repeat with a different name and work directly from source to executable:
gcc -o demohello hello.c -lm
and run again.
./demohello
it runs the same
Hello world
if we link the object file
gcc -o hello hello.o -lm
and run
./hello
we see no change
Hello world
Now we can build completely from source that we editied and run
gcc -o hello hello.c -lm
./hello
gcc --help
gcc -Wall -g -o hello hello.c -lm
-g: When used, GCC includes extra data in the compiled output, such as symbol names, types, source file names, and line numbers.
This information is crucial for debuggers like GDB, allowing developers to step through code, inspect variables, and understand the program’s execution flow.
17.18. Working with multiple files#
This all looks a bit different if we have our code split across files.
we will make a new file main.c
nano main.c
with content as follows
/* Used to illustrate separate compilation.
Created: Joe Zachary, October 22, 1992
Modified:
*/
#include <stdio.h>
void main () {
int n;
printf("Please enter a small positive integer: ");
scanf("%d", &n);
printf("The sum of the first n integers is %d\n", sum(n));
printf("The product of the first n integers is %d\n", product(n));
}
Then help.c
nano help.c
/* Used to illustrate separate compilation
Created: Joe Zachary, October 22, 1992
Modified:
*/
/* Requires that "n" be positive. Returns the sum of the
first "n" integers. */
int sum (int n) {
int i;
int total = 0;
for (i = 1; i <= n; i++)
total += i;
return(total);
}
/* Requires that "n" be positive. Returns the product of the
first "n" integers. */
int product (int n) {
int i;
int total = 1;
for (i = 1; i <= n; i++)
total *= i;
return(total);
}
Now we try again
gcc -Wall -g -c main.c
main.c:10:6: warning: return type of ‘main’ is not ‘int’ [-Wmain]
void main () {
^
main.c: In function ‘main’:
main.c:12:2: warning: implicit declaration of function ‘sum’ [-Wimplicit-function-declaration]
printf("The sum of the first n integers is %d\n", sum(n));
^
main.c:13:2: warning: implicit declaration of function ‘product’ [-Wimplicit-function-declaration]
printf("The product of the first n integers is %d\n", product(n));
^
we will leave only the one, which we will leave
Now we preprocess, compile and assemble the helper code:
gcc -Wall -g -c help.c
and look at what was created
ls
demohello hello.c hello.o help.c main.c
hello hello.i hello.s help.o main.o
Tip
One reason we split code is to make it readable, but another reason is what we just did. We can compile each file separately, when your code is large and compiling takes a long time, splitting it will mean you only have to recompile the file(s) you have recently changed and relink, instead of recompiling everything.
and finally we link them.
gcc -o demo main.o help.o -lm
and then we can run
./demo
Please enter a small positive integer: 5
The sum of the first n integers is 15
The product of the first n integers is 120
ls
demo hello hello.c help.c help.o main.c main.o
Please enter a small positive integer: 6
The sum of the first n integers is 21
The product of the first n integers is 720
exit
Now we can modify the code
int main(int argc, char *argv[]) {
int n = atoi(argv[1]);
printf("The sum of the first %d integers is %d\n", n, sum(n));
printf("The product of the first %d integers is %d\n", n, product(n));
return 0;
}
Notice that now that we’ve fixed main.c we only need to recompile that. There is no need to recompile help.c since nothing changed in its code. We really just need the machine code of the new main and then we need to link both help.o with the new main.o. Let’s call it main2.o
gcc -o main2.o -gc main.c
gcc -o demo main2.o help.o -lm
and then we can run
./demo
Segmentation fault
We made the new code accept an integer argument directly from the terminal. So if we don’t pass one, it trys to grab an unavailable value and fails like it did here
./demo 5
The sum of the first n integers is 15
The product of the first n integers is 120
17.19. batch jobs#
#!/bin/bash
#SBATCH -t 1:00:00
#SBATCH --nodes=1 --ntasks-per-node=1
./single_job
17.20. Experience Report Evidence#
17.21. Prepare for Next Class#
TBD
17.22. Badges#
Create some variations of the
hello.cwe made in class. Make hello2.c print twice with 2 print commands. Make hello5.c print 5 times with a for loop and hello7.c print 7 times with a for loop. Build them all on the command line and make sure they run correctly.Write a bash script, assembly.sh to compile each program to assembly and print the number of lines in each file.
use scp to download your modified main, script files, and output to your local computer and include them in your kwl repo.
Write a bash script demo_test.sh that runs your compiled program for each integer from 10 to 30 (syntax for a range is
{start..end}so this would be{10..30})Write a bash script, assembly.sh to compile each program to assembly and print the number of lines in each file.
Put the output of your script in hello_assembly_compare.md. Add to the file some notes on how they are similar or different based on your own reading of them.
use scp to download your modified main, script files, and output to your local computer and include them in your kwl repo.