
9. How do programmers communicate about code?#
Tip
check if your codespace has uncommitted changes on github.com/codespaces
note:
you can only have 2 active at a time(green dots)
you can see if any have uncommitted changes
you can export those changes to a branch from this page
9.1. Why Documentation#
Today we will talk about documentation, there are several reasons this is important:
using official documentation is the best way to get better at the tools
understanding how documentation is designed and built will help you use it better
writing and maintaining documentation is really important part of working on a team
documentation building tools are a type of developer tool (and these are generally good software design)
Design is best learned from examples. Some of the best examples of software design come from developer tools.
In particular documentation tools are really good examples of:
pattern matching
modularity and abstraction
automation
the build process beyond compiling
By the end of today’s class you will be able to:
describe different types of documentation
generate documentation as html
Plus we will reinforce things we have already seen:
paths
good file naming
9.2. What is documentation#
from ethnography of docuemtnation data science
9.2.1. Why is documentation so important?#
we should probably spend more time on it
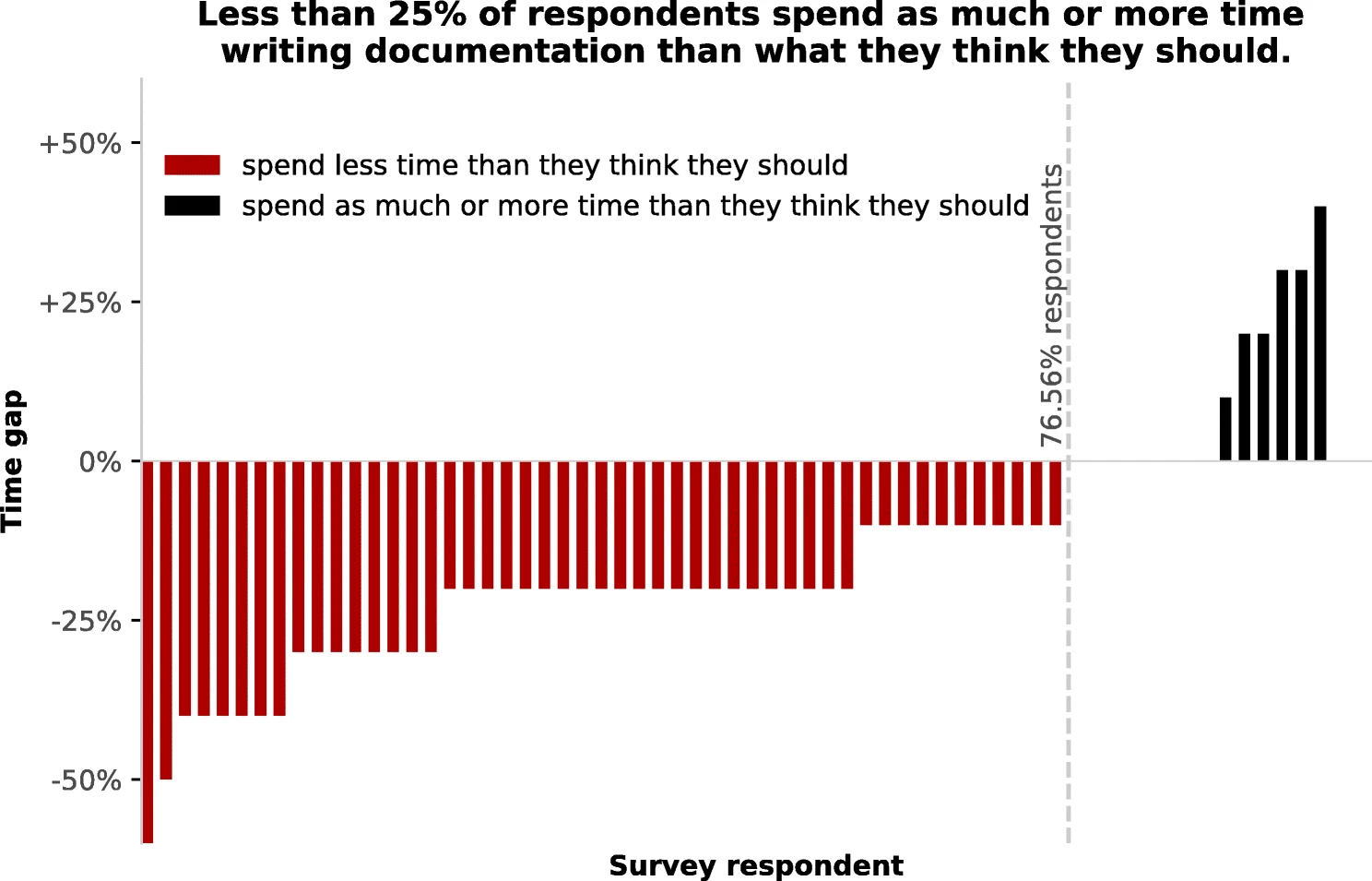
9.3. So, how do we do it?#
Different types of documentation live in different places and we use tools to maintain them.
As developers, we rely on code to do things that are easy for computers and hard for people.
linux kernel uses sphinx and here is why and how it works
9.4. Jupyterbook#
Jupyterbook wraps sphinx and uses markdown instead of restructured text. The project authors note in the documenation that it “can be thought of as an opinionated distribution of Sphinx”. We’re goign to use this.
navigate to your folder for this course (mine is inclass/systems)
We can confirm that jupyter-book is installed by checking the version.
jupyter-book --version
Jupyter Book : 1.0.2
External ToC : 1.0.1
MyST-Parser : 2.0.0
MyST-NB : 1.1.1
Sphinx Book Theme : 1.1.3
Jupyter-Cache : 1.0.0
NbClient : 0.10.0
Let’s look at the status of this folder to set a baseline before we run new commands.
ls
fall24-brownsarahm gh-inclass-brownsarahm
We will run a command to create a jupyterbook from a template, the command has 3 parts:
jupyter-bookis a program (the thing we installed)createis a subcommand (one action that program can do)tiny-bookis an argument (a mandatory input to that action)
jupyter-book create tiny-book
===============================================================================
Your book template can be found at
tiny-book/
===============================================================================
but it does an unrelated thing, we can use ls to check again to see more of what happened beyond the annoucnement above
ls
we have a new folder!
fall24-brownsarahm tiny-book
gh-inclass-brownsarahm
You can make it with any name:
jupyter-book create example
beacuse the name is an argument or input
===============================================================================
Your book template can be found at
example/
===============================================================================
Each one makes a directory, we can see by listing
ls
example gh-inclass-brownsarahm
fall24-brownsarahm tiny-book
And we can delete the second one since we do not actually want it.
rm example/
rm: example/: is a directory
we get an error because it is not well defined to delete a directory, and potentially risky, so rm is written to throw an error
Instead, we have to tell it two additional things:
to delete recusively
rto force it to do something risky with
f
note we can stack single character options together with a single -
rm -rf example/
ls
fall24-brownsarahm tiny-book
gh-inclass-brownsarahm
as we want
9.5. Structure of a Jupyter book#
cd tiny-book/
We will explore the output by looking at the files
ls
_config.yml markdown.md
_toc.yml notebooks.ipynb
intro.md references.bib
logo.png requirements.txt
markdown-notebooks.md
A jupyter book has two required files (_config.yml and _toc.yml), some for content, and some helpers that are common but not required.
the
*.mdfiles are contentthe
.bibfile is bibiolography informationThe other files are optional, but common. Requirements.txt is the format for pip to install python depndencies. There are different standards in other languages for how
Note
the extention (.yml) is yaml, which stands for “YAML Ain’t Markup Language”. It consists of key, value pairs and is deigned to be a human-friendly way to encode data for use in any programming language.
9.5.1. Dev tools mean we do not have to write bibliographies manually#
bibliographies are generated with bibtex which takes structured information from the references in a bibtex file with help from sphinxcontrib-bibtex
For general reference, reference managers like zotero and mendeley can track all of your sources and output the references in bibtex format that you can use anywhere or sync with tools like MS Word or Google Docs.
this is not a git repo it is only a folder we have made locally
git status
fatal: not a git repository (or any of the parent directories): .git
cat references.bib
@inproceedings{holdgraf_evidence_2014,
address = {Brisbane, Australia, Australia},
title = {Evidence for {Predictive} {Coding} in {Human} {Auditory} {Cortex}},
booktitle = {International {Conference} on {Cognitive} {Neuroscience}},
publisher = {Frontiers in Neuroscience},
author = {Holdgraf, Christopher Ramsay and de Heer, Wendy and Pasley, Brian N. and Knight, Robert T.},
year = {2014}
}
@article{holdgraf_rapid_2016,
title = {Rapid tuning shifts in human auditory cortex enhance speech intelligibility},
volume = {7},
issn = {2041-1723},
url = {http://www.nature.com/doifinder/10.1038/ncomms13654},
doi = {10.1038/ncomms13654},
number = {May},
journal = {Nature Communications},
author = {Holdgraf, Christopher Ramsay and de Heer, Wendy and Pasley, Brian N. and Rieger, Jochem W. and Crone, Nathan and Lin, Jack J. and Knight, Robert T. and Theunissen, Frédéric E.},
year = {2016},
pages = {13654},
file = {Holdgraf et al. - 2016 - Rapid tuning shifts in human auditory cortex enhance speech intelligibility.pdf:C\:\\Users\\chold\\Zotero\\storage\\MDQP3JWE\\Holdgraf et al. - 2016 - Rapid tuning shifts in human auditory cortex enhance speech intelligibility.pdf:application/pdf}
}
@inproceedings{holdgraf_portable_2017,
title = {Portable learning environments for hands-on computational instruction using container-and cloud-based technology to teach data science},
volume = {Part F1287},
isbn = {978-1-4503-5272-7},
doi = {10.1145/3093338.3093370},
abstract = {© 2017 ACM. There is an increasing interest in learning outside of the traditional classroom setting. This is especially true for topics covering computational tools and data science, as both are challenging to incorporate in the standard curriculum. These atypical learning environments offer new opportunities for teaching, particularly when it comes to combining conceptual knowledge with hands-on experience/expertise with methods and skills. Advances in cloud computing and containerized environments provide an attractive opportunity to improve the effciency and ease with which students can learn. This manuscript details recent advances towards using commonly-Available cloud computing services and advanced cyberinfrastructure support for improving the learning experience in bootcamp-style events. We cover the benets (and challenges) of using a server hosted remotely instead of relying on student laptops, discuss the technology that was used in order to make this possible, and give suggestions for how others could implement and improve upon this model for pedagogy and reproducibility.},
booktitle = {{ACM} {International} {Conference} {Proceeding} {Series}},
author = {Holdgraf, Christopher Ramsay and Culich, A. and Rokem, A. and Deniz, F. and Alegro, M. and Ushizima, D.},
year = {2017},
keywords = {Teaching, Bootcamps, Cloud computing, Data science, Docker, Pedagogy}
}
@article{holdgraf_encoding_2017,
title = {Encoding and decoding models in cognitive electrophysiology},
volume = {11},
issn = {16625137},
doi = {10.3389/fnsys.2017.00061},
abstract = {© 2017 Holdgraf, Rieger, Micheli, Martin, Knight and Theunissen. Cognitive neuroscience has seen rapid growth in the size and complexity of data recorded from the human brain as well as in the computational tools available to analyze this data. This data explosion has resulted in an increased use of multivariate, model-based methods for asking neuroscience questions, allowing scientists to investigate multiple hypotheses with a single dataset, to use complex, time-varying stimuli, and to study the human brain under more naturalistic conditions. These tools come in the form of “Encoding” models, in which stimulus features are used to model brain activity, and “Decoding” models, in which neural features are used to generated a stimulus output. Here we review the current state of encoding and decoding models in cognitive electrophysiology and provide a practical guide toward conducting experiments and analyses in this emerging field. Our examples focus on using linear models in the study of human language and audition. We show how to calculate auditory receptive fields from natural sounds as well as how to decode neural recordings to predict speech. The paper aims to be a useful tutorial to these approaches, and a practical introduction to using machine learning and applied statistics to build models of neural activity. The data analytic approaches we discuss may also be applied to other sensory modalities, motor systems, and cognitive systems, and we cover some examples in these areas. In addition, a collection of Jupyter notebooks is publicly available as a complement to the material covered in this paper, providing code examples and tutorials for predictive modeling in python. The aimis to provide a practical understanding of predictivemodeling of human brain data and to propose best-practices in conducting these analyses.},
journal = {Frontiers in Systems Neuroscience},
author = {Holdgraf, Christopher Ramsay and Rieger, J.W. and Micheli, C. and Martin, S. and Knight, R.T. and Theunissen, F.E.},
year = {2017},
keywords = {Decoding models, Encoding models, Electrocorticography (ECoG), Electrophysiology/evoked potentials, Machine learning applied to neuroscience, Natural stimuli, Predictive modeling, Tutorials}
}
@book{ruby,
title = {The Ruby Programming Language},
author = {Flanagan, David and Matsumoto, Yukihiro},
year = {2008},
publisher = {O'Reilly Media}
}
9.6. YAML files let us set parameters in a file#
The table of contents file describe how to put the other files in order.
cat _toc.yml
1# Table of contents
2# Learn more at https://jupyterbook.org/customize/toc.html
The first two lines are comments, the pound sign # is a comment in bash and
YAML. Here, the developers chose, in the template to put information about how to
set up this file right in the template file. This is developers helping their users!
4format: jb-book
5root: intro
The first next two lines are key value pairs that tell the high level settings
6chapters:
7- file: markdown
8- file: notebooks
9- file: markdown-notebooks
the end of the file shows a list of files that will be treated as chapters. This is also the syntax
for a list in YAML, the list is named chapters and each item, starting with a - has a single key, file
Where have we seen a YAML list?
You can create a community badge that uses as the location of the “contribution” a link to the snipped to a set of lines in your main fall24 repo that is a YAML list. This is valid as long as it is created before lab time on Monday October 7.
Config tells jupyter-book how to run, these are literally the options and settings
it needs to make a site (or other document).
cat _config.yml
# Book settings
# Learn more at https://jupyterbook.org/customize/config.html
title: My sample book
author: The Jupyter Book Community
logo: logo.png
# Force re-execution of notebooks on each build.
# See https://jupyterbook.org/content/execute.html
execute:
execute_notebooks: force
# Define the name of the latex output file for PDF builds
latex:
latex_documents:
targetname: book.tex
# Add a bibtex file so that we can create citations
bibtex_bibfiles:
- references.bib
# Information about where the book exists on the web
repository:
url: https://github.com/executablebooks/jupyter-book # Online location of your book
path_to_book: docs # Optional path to your book, relative to the repository root
branch: master # Which branch of the repository should be used when creating links (optional)
# Add GitHub buttons to your book
# See https://jupyterbook.org/customize/config.html#add-a-link-to-your-repository
html:
use_issues_button: true
use_repository_button: true
Here the develoeprs left many links to more information and included default values for several settings that people might want to change easily.
9.6.1. Retiring racist language#
Historically the default branch in git was called master. jupyter-book has that as default
derived from a master/slave analogy which is not even how git works, but was adopted terminology from other projects
literally the person who chose the names “master” and “origin” regrets that choice the name main is a more accurate and not harmful term and the current convention.
9.7. Files can help us install dependencies too#
The one last file tells us what dependencies we have
cat requirements.txt
If your book generates with error messages run pip install -r requirements.txt
jupyter-book
matplotlib
numpy
Thse are two python libraries that are required to run the code in the notebook files, plus jupyter-book itself.
ls
_config.yml markdown.md
_toc.yml notebooks.ipynb
intro.md references.bib
logo.png requirements.txt
markdown-notebooks.md
9.8. Building Documentation#
We can transform from raw source to an output by building the book
jupyter-book build .
Running Jupyter-Book v1.0.2
Source Folder: /Users/brownsarahm/Documents/inclass/systems/tiny-book
Config Path: /Users/brownsarahm/Documents/inclass/systems/tiny-book/_config.yml
Output Path: /Users/brownsarahm/Documents/inclass/systems/tiny-book/_build/html
Running Sphinx v7.4.7
loading translations [en]... done
making output directory... done
[etoc] Changing master_doc to 'intro'
checking bibtex cache... out of date
parsing bibtex file /Users/brownsarahm/Documents/inclass/systems/tiny-book/references.bib... parsed 5 entries
myst v2.0.0: MdParserConfig(commonmark_only=False, gfm_only=False, enable_extensions={'linkify', 'dollarmath', 'colon_fence', 'substitution', 'tasklist'}, disable_syntax=[], all_links_external=False, url_schemes=('mailto', 'http', 'https'), ref_domains=None, fence_as_directive=set(), number_code_blocks=[], title_to_header=False, heading_anchors=0, heading_slug_func=None, html_meta={}, footnote_transition=True, words_per_minute=200, substitutions={}, linkify_fuzzy_links=True, dmath_allow_labels=True, dmath_allow_space=True, dmath_allow_digits=True, dmath_double_inline=False, update_mathjax=True, mathjax_classes='tex2jax_process|mathjax_process|math|output_area', enable_checkboxes=False, suppress_warnings=[], highlight_code_blocks=True)
myst-nb v1.1.1: NbParserConfig(custom_formats={}, metadata_key='mystnb', cell_metadata_key='mystnb', kernel_rgx_aliases={}, eval_name_regex='^[a-zA-Z_][a-zA-Z0-9_]*$', execution_mode='force', execution_cache_path='', execution_excludepatterns=[], execution_timeout=30, execution_in_temp=False, execution_allow_errors=False, execution_raise_on_error=False, execution_show_tb=False, merge_streams=False, render_plugin='default', remove_code_source=False, remove_code_outputs=False, code_prompt_show='Show code cell {type}', code_prompt_hide='Hide code cell {type}', number_source_lines=False, output_stderr='show', render_text_lexer='myst-ansi', render_error_lexer='ipythontb', render_image_options={}, render_figure_options={}, render_markdown_format='commonmark', output_folder='build', append_css=True, metadata_to_fm=False)
Using jupyter-cache at: /Users/brownsarahm/Documents/inclass/systems/tiny-book/_build/.jupyter_cache
sphinx-multitoc-numbering v0.1.3: Loaded
building [mo]: targets for 0 po files that are out of date
writing output...
building [html]: targets for 4 source files that are out of date
updating environment: [new config] 4 added, 0 changed, 0 removed
/Users/brownsarahm/Documents/inclass/systems/tiny-book/markdown-notebooks.md: Executing notebook using local CWD [mystnb]
/Users/brownsarahm/Documents/inclass/systems/tiny-book/markdown-notebooks.md: Executed notebook in 4.13 seconds [mystnb]
/Users/brownsarahm/Documents/inclass/systems/tiny-book/notebooks.ipynb: Executing notebook using local CWD [mystnb]
/Users/brownsarahm/Documents/inclass/systems/tiny-book/notebooks.ipynb: Executed notebook in 2.45 seconds [mystnb]
looking for now-outdated files... none found
pickling environment... done
checking consistency... done
preparing documents... done
copying assets...
copying static files... done
copying extra files... done
copying assets: done
writing output... [100%] notebooks
generating indices... genindex done
writing additional pages... search done
copying images... [100%] _build/jupyter_execute/a31e63b1f6ca34376ef17d2b6c277648c6b47bb0a75c5165999735167a988593.png
dumping search index in English (code: en)... done
dumping object inventory... done
[etoc] missing index.html written as redirect to 'intro.html'
build succeeded.
The HTML pages are in _build/html.
===============================================================================
Finished generating HTML for book.
Your book's HTML pages are here:
_build/html/
You can look at your book by opening this file in a browser:
_build/html/index.html
Or paste this line directly into your browser bar:
file:///Users/brownsarahm/Documents/inclass/systems/tiny-book/_build/html/index.html
===============================================================================
9.9. Documentation engines use patterns#
These are a structure that a lot of programming languages and other contexts
See examples in other langauges in their documentation:
the liquid templating language is used for shopify and used in a few other technologies
I can do a quick python example by starting a python interpretter.
'ldksjfsdfj {my_var} sflksjflsdk'.format(my_var ='hello')
'ldksjfsdfj hello sflksjflsdk'
We can see it added a folder
ls
_build markdown-notebooks.md
_config.yml markdown.md
_toc.yml notebooks.ipynb
intro.md references.bib
logo.png requirements.txt
the _build fodler is new
and we can look at the top of the contents ( you can inspect fully in your repo, but this output would be long with cat and the point here is not to know the details of HTML, but to trust that it can be added formulaically)
head _build/html/index.html
<meta http-equiv="Refresh" content="0; url=intro.html" />
we can see how many files it made
ls _build/html/
_images markdown-notebooks.html
_sources markdown.html
_sphinx_design_static notebooks.html
_static objects.inv
genindex.html search.html
index.html searchindex.js
intro.html
there is
one html file for each source file from the toc
a fodler for images
the source code
some files that help the search
an index page
and a
_staticfolder for the css to style the page
9.10. Prepare for Next Class#
review the notes on what is a commit. In gitdef.md on the branch for this issue, try to describe git in the four ways we described a commit. the point here is to think about what you know for git and practice remembering it, not “get the right answer”; this is prepare work, we only check that it is complete, not correct
Start recording notes on how you use IDEs for the next couple of weeks using the template file below. We will come back to these notes in class later, but it is best to record over a time period instead of trying to remember at that time. Store your notes in your fall24 repo in idethoughts.md on a dedicated
ide_prepbranch. This is prep for after a few weeks from now, not for October 8; keep this branch open until it is specifically asked for
9.11. Badges#
Review the notes, jupyterbook docs, and experiment with the
jupyter-bookCLI to determine what files are required to makejupyter-book buildrun. Make your kwl repo into a jupyter book, by manually adding those files. do not add the whole template to your repo, make the content you have already so it can build into html. Set it so that the_builddirectory is not under version control.Add
docs-review.mdto your KWL repo and explain the most important things to know about documentation in your own words using other programming concepts you have learned so far. Include in a markdown (same as HTML<!-- comment -->) comment the list of CSC courses you have taken for context while we give you feedback.
Review the notes, jupyterbook docs, and experiment with the
jupyter-bookCLI to determine what files are required to makejupyter-book buildrun. Make your kwl repo into a jupyter book. Set it so that the_builddirectory is not under version control.Learn about the documentation ecosystem in another language that you know using at least one official source and additional sources as you find helpful. In
docs-practice.mdinclude a summary of your findings and compare and contrast it to jupyter book/sphinx. Include a bibtex based bibliography of the sources you used. You can use this generator for informal sources and google scholar for formal sources (or a reference manager).
9.12. Experience Report Evidence#
9.13. Questions After Today’s Class#
Important
Windows users should see the Windows Help & Notes page for help
9.13.1. What are some similar tools to jupyter-book?#
Note
We are using jupyter-book which is different from jupyter notebook
Jupyter-book is similar to sphinx because it uses it.
There are a lot of other Documenation Tools.
mystmd is a newer project that is a lot like jupyter (made by the same people) designed for publishing like with curvenote or vercel
Another similar tool is quarto
and in some ways pandoc is also similar
Important
using any of these tools is a valid build idea
9.13.2. Is it technically a Platform as a service?#
No, it is just a program tht transforms our content from one to another.
9.13.3. does jupyter-book have to be referenced anywhere when used to create something?#
No you do not have to say that you used it to create your content, but you can. For example, in commit 947fdff I add that to the footer of this site.