
Badge Deadlines and Procedures#
This page includes more visual versions of the information on the badge page. You should read both, but this one is often more helpful, because some of the processes take a lot of words to explain and make more sense with a diagram for a lot of people.
Show code cell source
%matplotlib inline
import os
from datetime import date,timedelta
import calendar
import pandas as pd
import numpy as np
import seaborn as sns
from myst_nb import glue
# style note: when I wrote this code, it was not all one cell. I merged the cells
# for display on the course website, since Python is not the main outcome of this course
# semester settings
first_day = date(2024,1,23)
last_day = date(2024,4,29)
# no_class_ranges = [(date(2023,11,23),date(2023,11,26)),
# (date(2023,11,13)),
# (date(2023,10,10))]
no_class_ranges = [(date(2024,3,10),date(2024,3,16)),
(date(2024,2,19))]
meeting_days =[1,3] # datetime has 0=Monday
penalty_free_end = date(2024, 2, 9)
def day_off(cur_date,skip_range_list=no_class_ranges):
'''
is the current date a day off?
Parameters
----------
cur_date : datetime.date
date to check
skip_range_list : list of datetime.date objects or 2-tuples of datetime.date
dates where there is no class, either single dates or ranges specified by a tuple
Returns
-------
day_is_off : bool
True if the day is off, False if the day has class
'''
# default to not a day off
day_is_off=False
#
for skip_range in skip_range_list:
if type(skip_range) == tuple:
# if any of the conditions are true that increments and it will never go down, flase=0, true=1
day_is_off += skip_range[0]<=cur_date<=skip_range[1]
else:
day_is_off += skip_range == cur_date
#
return day_is_off
# enumerate weeks
mtg_delta = timedelta(meeting_days[1]-meeting_days[0])
week_delta = timedelta(7)
weeks = 14
possible = [(first_day+week_delta*w, first_day+mtg_delta+week_delta*w) for w in range(weeks)]
weekly_meetings = [[c1,c2] for c1,c2 in possible if not(day_off(c1,no_class_ranges))]
meetings = [m for w in weekly_meetings for m in w]
meetings_string = [m.isoformat() for m in meetings]
weekly_meetings
# possible = [(first_day+week_delta*w, first_day+mtg_delta+week_delta*w) for w in range(weeks)]
# weekly_meetings = [[c1,c2] for c1,c2 in possible if not(during_sb(c1))]
meetings = [m for w in weekly_meetings for m in w if not(day_off(m))]
# build a table for the dates
badge_types = ['experience', 'review', 'practice']
target_cols = ['review_target','practice_target']
df_cols = badge_types + target_cols
badge_target_df = pd.DataFrame(index=meetings, data=[['future']*len(df_cols)]*len(meetings),
columns=df_cols).reset_index().rename(
columns={'index': 'date'})
# set relative dates
today = date.today()
start_deadline = date.today() - timedelta(7)
complete_deadline = date.today() - timedelta(14)
# mark eligible experience badges
badge_target_df['experience'][badge_target_df['date'] <= today] = 'eligible'
# mark targets, cascading from most recent to oldest to not have to check < and >
badge_target_df['review_target'][badge_target_df['date'] <= today] = 'active'
badge_target_df['practice_target'][badge_target_df['date'] <= today] = 'active'
badge_target_df['review_target'][badge_target_df['date']
<= start_deadline] = 'started'
badge_target_df['practice_target'][badge_target_df['date']
<= start_deadline] = 'started'
badge_target_df['review_target'][badge_target_df['date']
<= complete_deadline] = 'completed'
badge_target_df['practice_target'][badge_target_df['date']
<= complete_deadline] = 'completed'
# mark enforced deadlines
badge_target_df['review'][badge_target_df['date'] <= today] = 'active'
badge_target_df['practice'][badge_target_df['date'] <= today] = 'active'
badge_target_df['review'][badge_target_df['date']
<= start_deadline] = 'started'
badge_target_df['practice'][badge_target_df['date']
<= start_deadline] = 'started'
badge_target_df['review'][badge_target_df['date']
<= complete_deadline] = 'completed'
badge_target_df['practice'][badge_target_df['date']
<= complete_deadline] = 'completed'
badge_target_df['review'][badge_target_df['date']
<= penalty_free_end] = 'penalty free'
badge_target_df['practice'][badge_target_df['date']
<= penalty_free_end] = 'penalty free'
# convert to numbers and set dates as index for heatmap compatibility
status_numbers_hm = {status:i+1 for i,status in enumerate(['future','eligible','active','penalty free','started','completed'])}
badge_target_df_hm = badge_target_df.replace(status_numbers_hm).set_index('date')
# set column names to shorter ones to fit better
badge_target_df_hm = badge_target_df_hm.rename(columns={'review':'review(e)','practice':'practice(e)',
'review_target':'review(t)','practice_target':'practice(t)',})
# build a custom color bar
n_statuses = len(status_numbers_hm.keys())
manual_palette = [sns.color_palette("pastel", 10)[7],
sns.color_palette("colorblind", 10)[2],
sns.color_palette("muted", 10)[2],
sns.color_palette("colorblind", 10)[9],
sns.color_palette("colorblind", 10)[8],
sns.color_palette("colorblind", 10)[3]]
# generate the figure, with the colorbar and spacing
ax = sns.heatmap(badge_target_df_hm,cmap=manual_palette,linewidths=1)
# mote titles from bottom tot op
ax.xaxis.tick_top()
# pull the colorbar object for handling
colorbar = ax.collections[0].colorbar
# fix the location fo the labels on the colorbar
r = colorbar.vmax - colorbar.vmin
colorbar.set_ticks([colorbar.vmin + r / n_statuses * (0.5 + i) for i in range(n_statuses)])
colorbar.set_ticklabels(list(status_numbers_hm.keys()))
# add a title
today_string = today.isoformat()
glue('today',today_string,display=False)
glue('today_notdisplayed',"not today",display=False)
ax.set_title('Badge Status as of '+ today_string);
/tmp/ipykernel_2263/4025995832.py:90: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['experience'][badge_target_df['date'] <= today] = 'eligible'
/tmp/ipykernel_2263/4025995832.py:92: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['review_target'][badge_target_df['date'] <= today] = 'active'
/tmp/ipykernel_2263/4025995832.py:93: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['practice_target'][badge_target_df['date'] <= today] = 'active'
/tmp/ipykernel_2263/4025995832.py:94: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['review_target'][badge_target_df['date']
/tmp/ipykernel_2263/4025995832.py:96: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['practice_target'][badge_target_df['date']
/tmp/ipykernel_2263/4025995832.py:98: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['review_target'][badge_target_df['date']
/tmp/ipykernel_2263/4025995832.py:100: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['practice_target'][badge_target_df['date']
/tmp/ipykernel_2263/4025995832.py:103: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['review'][badge_target_df['date'] <= today] = 'active'
/tmp/ipykernel_2263/4025995832.py:104: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['practice'][badge_target_df['date'] <= today] = 'active'
/tmp/ipykernel_2263/4025995832.py:105: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['review'][badge_target_df['date']
/tmp/ipykernel_2263/4025995832.py:107: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['practice'][badge_target_df['date']
/tmp/ipykernel_2263/4025995832.py:109: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['review'][badge_target_df['date']
/tmp/ipykernel_2263/4025995832.py:111: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['practice'][badge_target_df['date']
/tmp/ipykernel_2263/4025995832.py:113: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['review'][badge_target_df['date']
/tmp/ipykernel_2263/4025995832.py:115: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
badge_target_df['practice'][badge_target_df['date']
/tmp/ipykernel_2263/4025995832.py:120: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
badge_target_df_hm = badge_target_df.replace(status_numbers_hm).set_index('date')
Text(0.5, 1.0, 'Badge Status as of 2024-09-06')
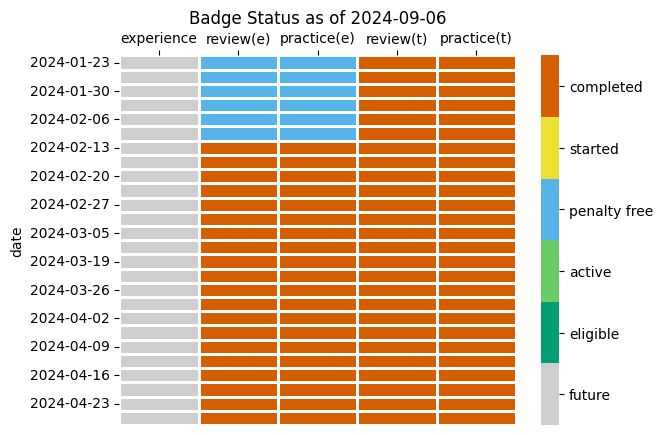
Deadlines#
We do not have a final exam, but URI assigns an exam time for every class. The date of that assigned exam will be the final due date for all work including all revisions.
Experience badges#
Prepare for class tasks must be done before class so that you are prepared. Missing a prepare task could require you to do an experience report to make up what you were not able to do in class.
If you miss class, the experience report should be at least attempted/drafted (though you may not get feedback/confirmation) before the next class that you attend. This is strict, not as punishment, but to ensure that you are able to participate in the next class that you attend. Skipping the experience report for a missed class, may result in needing to do an experience report for the next class you attend to make up what you were not able to complete due to the missing class activities.
If you miss multiple classes, create a catch-up plan to get back on track by contacting Dr. Brown.
Review and Practice Badges#
These badges have 5 stages:
posted: tasks are on the course website
planned: an issue is created
started: one task is attempted and a draft PR is open
completed: all tasks are attempted PR is ready for review, and a review is requested
earned: PR is approved (by instructor or a TA) and work is merged
Tip
these badges should be started before the next class. This will set you up to make the most out of each class session. However, only prepare for class tasks have to be done immediately.
These badges badges must be started within one week of when the are posted (2pm) and completed within two weeks. A task is attempted when you have answered the questions or submitted evidence of doing an activity or asked a sincere clarifying question.
If a badge is planned, but not started within one week it will become expired and ineligble to be earned. You may request extensions to complete a badge by updating the PR message, these will typically be granted. Extensions for starting badges will only be granted in exceptional circumstances.
Expired badges will receive a comment and be closed
Once you have a good-faith attempt at a complete badge, you have until the end of the semester to finish the revisions in order to earn the badge.
Tip
Try to complete revisions quickly, it will be easier for you
Explore Badges#
Explore badges have 5 stages:
proposed: issue created
in progress: issue is labeled “proceed” by the instructor
complete: work is complete, PR created, review requested
revision: “request changes” review was given
earned: PR approved
Explore badges are feedback-limited. You will not get feedback on subsequent explore badge proposals until you earn the first one. Once you have one earned, then you can have up to two in progress and two in revision at any given time. At most, you will receive feedback for one explore badge per week, so in order to earn six, your first one must be complete by March 18.
Build Badges#
At most one build badge will be evaluated every 4 weeks. This means that if you want to earn 3 build badges, the first one must be in 8 weeks before the end of the semester, March 4. The second would be due April 1st, and the third submitted by the end of classes, April 29th.
Prepare work and Experience Badges Process#
This is for a single example with specific dates, but it is similar for all future dates
The columns (and purple boxes) correspond to branches in your KWL repo and the yellow boxes are the things that you have to do. The “critical” box is what you have to wait for us on. The arrows represent PRs (or a local merge for the first one)
In the end the commit sequence for this will look like the following:
Where the “approved” tag represents and approving reivew on the PR.
Review and Practice Badge#
Legend:
This is the general process for review and practice badges
Explore Badges#
Build Badges#
Community Badges#
These are the instructions from your community_contributions.md file in your KWL repo:
For each one:
In the `community_contributions.md`` file on your kwl repo, add an item in a bulleted list (start the line with - )
Include a link to your contribution like
[text to display](url/of/contribution)create an individual pull request titled “Community-shortname” where
shortnameis a short name for what you did. approval on this PR by Dr. Brown will constitute credit for your graderequest a review on that PR from @brownsarahm
Important
You want one contribution per PR` for tracking